
Представьте, что вы настроили новую автоматизацию в Home Assistant. Всё отладили, протестировали — работает. День работает, два работает, вы уже постепенно привыкаете к изменениям, а потом ррр-раз!, и в ответственный момент всё отваливается. И как назло, вас не было дома, поэтому вы не сразу заметили проблему.
Начинаете разбираться, открываете логи, а там куча ошибок. Бывало такое?
Вот у меня подобное происходило много раз, и, думаю, не только у меня. Причем если, например, какая-то лампочка затупила и не включилась в нужное время, то это сразу заметно. А вот если не пришло напоминание о замене фильтров для воды, то такое легко упустить, потому что подобные уведомления приходят раз в 3 месяца.
В итоге в какой-то момент я заморочился и настроил мониторинг логов. Стабильность системы таким образом повысить не получится, но зато хотя бы можно отлавливать ошибки, которые раньше оставались без внимания.
Для мониторинга логов большие дяди обычно используют ELK, Graylog и прочие подобные системы, но для домашнего сервера это перебор. Поэтому я хочу рассказать про два варианта попроще:
- Про отправку уведомлений об ошибках в Telegram;
- И про мониторинг ошибок через Icinga 2 (то, что использую я).
Но для начала нужно сделать так, чтобы ошибки можно было перехватывать в автоматизациях.
Отлавливаем ошибки в Home Assistant
В Home Assistant есть возможность настроить автоматизацию, которая бы срабатывала при появлении ошибок или предупреждений. Только прежде чем создавать такую автоматизацию, необходимо включить генерацию событий из логов в configuration.yaml:
system_log:
fire_event: trueЭто позволяет нам использовать вот такой триггер:
triggers:
- trigger: event
event_type: system_log_event
event_data:
level: ERRORОтправляем уведомления об ошибках в Telegram
Остаётся только собрать всё вместе и добавить вот такую автоматизацию для пересылки событий об ошибках:
automation:
- alias: "Report system log errors"
mode: single
triggers:
- trigger: event
event_type: system_log_event
event_data:
level: ERROR
conditions:
- condition: template
value_template: "{{ trigger.event.data.name not in ['homeassistant.components.websocket_api.http.connection', 'homeassistant.helpers.event', 'aiohttp.server', 'custom_components.narodmon'] }}" # ошибки в каких компонентах можно игнорировать
actions:
- action: notify.telegram_roland
data:
message: "<code>{{ trigger.event.data.message[0] }}</code>" # берем первую строку
data:
disable_web_page_preview: True
parse_mode: html
- delay: "00:01:00" # «блокируем» автоматизацию на минуту, чтобы не было спамаКстати про Telegram, знаете у кого там есть канал? 😉
По самой автоматизации, надеюсь, вопросов не возникнет, но на всякий случай я добавил комментарии по отдельным моментам. В итоге после перезапуска Home Assistant вам начнут приходить уведомления в случае ошибок:
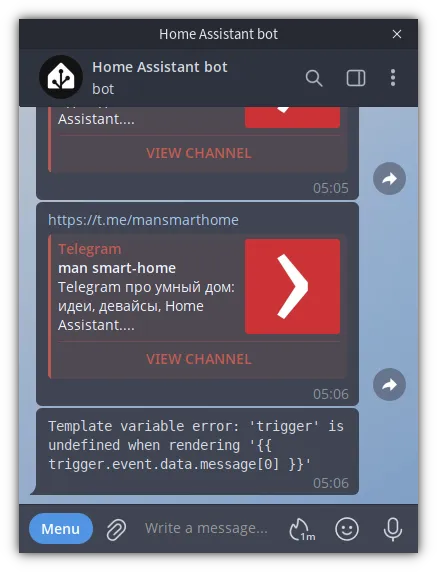
А если у вас еще нет Telegram-бота, то руководство по настройке можно найти на сайте Home Assistant.
Но отправка уведомлений в мессенджер — это не интересно. Telegram есть у всех, и поэтому я часто его использую в примерах, но для мониторинга серверов у меня настроена Icinga 2.
Мониторинг логов через Icinga 2
Вообще Icinga не особо предназначена для того, чтобы слать в неё логи напрямую, но кто мне запретит? 🙂 Тем более Icinga у меня уже давно настроена, в ней централизованно собираются данные по всем серверам, и поэтому логично использовать единую систему для мониторинга всего, в том числе для мониторинга ошибок Home Assistant.
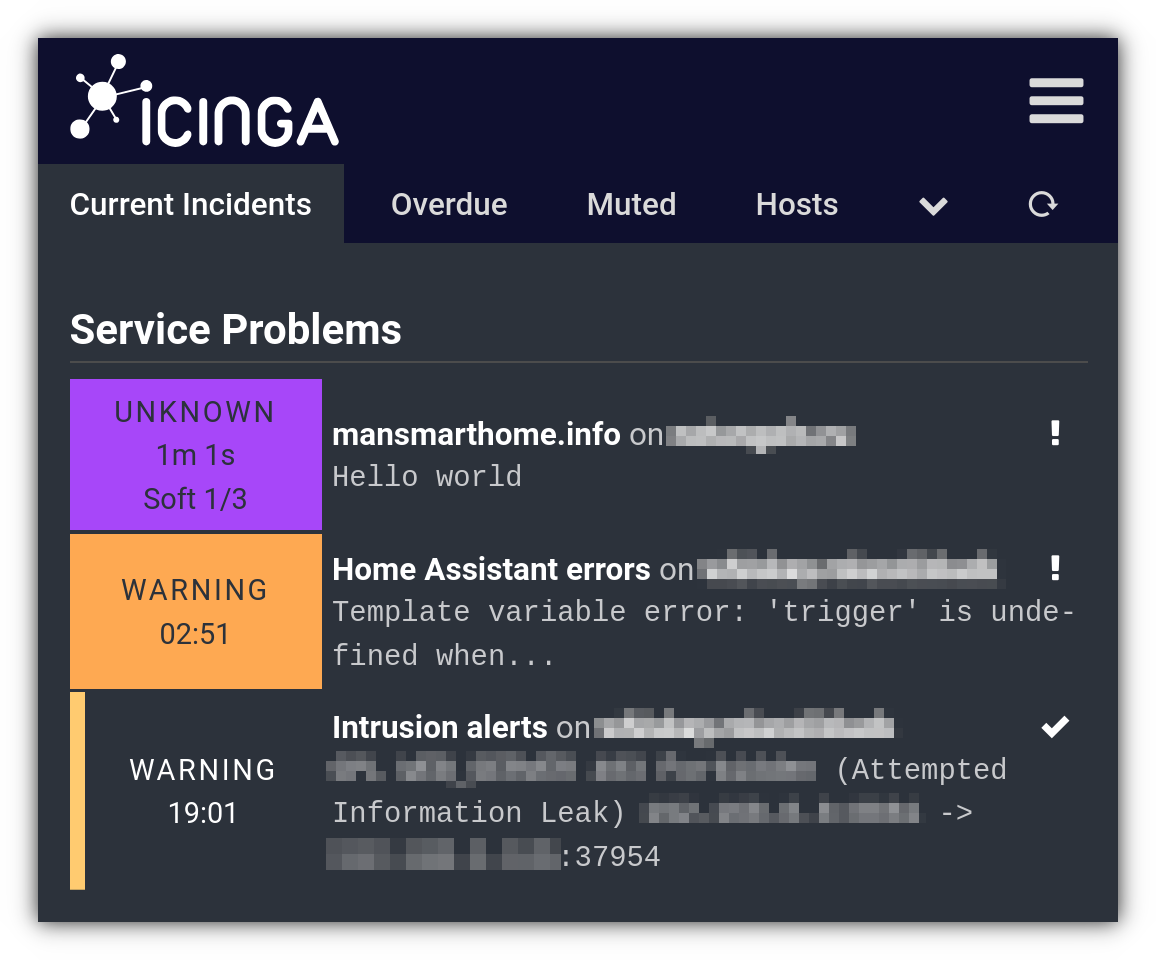
В Icinga есть два типа проверок: активные и пассивные. Активные проверки — это плагины, которые запускаются периодически и возвращают текущее состояние хоста или сервиса. А в случае с пассивными проверками, Icinga просто ждёт, когда состояние сервиса будет отправлено по API.
В нашем случае понадобится и то и другое:
- При возникновении ошибок Home Assistant будет передавать информацию о проблеме в «пассивный» API;
- А вот активная проверка нужна для того, чтобы периодически сбрасывать состояние Home Assistant в «OK».
Давайте начнём с того, что определим новый сервис в конфиге Icinga (в conf.d/services.conf или в zones.d/<имя_зоны>/services.conf):
apply Service "hass-system-log-errors" {
display_name = "Home Assistant errors"
enable_active_checks = true
enable_passive_checks = true
check_command = "passive" # dummy проверка, которая просто устанавливает нужное состояние
vars.dummy_state = 0
vars.dummy_text = "No errors for the last 24 hours"
check_interval = 24h # сбрасывать состояние сервиса в 0 (vars.dummy_state) через 24 часа
retry_interval = 24h
max_check_attempts = 1 # уведомлять сразу
volatile = true # присылать уведомления на каждую ошибку, а не 1 раз в 24 часа
assign where host.name == "<имя хоста, где запущен Home Assistant>"
# если помимо логов вы еще мониторите доступность HASS по HTTP, то можно использовать немного другое условие:
# assign where host.vars.http_vhosts["hass.my-home-server.org"]
}Затем нужно добавить нового пользователя в conf.d/api-users.conf:
object ApiUser "hass" {
password = "pa$$w0rd"
permissions = [ "actions/process-check-result" ]
}И в конце нужно применить новую конфигурацию:
# icinga2 daemon -C
# systemctl reload icinga2Осталось настроить отправку ошибок из Home Assistant. Для этого определим новую REST-команду в configuration.yaml:
rest_command:
report_error_to_icinga2:
url: "https://<сервер_мониторинга>:5665/v1/actions/process-check-result"
method: POST
headers:
accept: "application/json"
content_type: "application/json; charset=utf-8"
username: "hass" # логин…
password: "pa$$w0rd" # …и пароль, которые были заданы в api-users.conf
verify_ssl: false
payload: >
{ "type": "Service", "filter": "service.name==\"hass-system-log-errors\"", "exit_status": 1, "plugin_output": {{ message | to_json }} }И добавим новую автоматизацию:
automation:
- alias: "Report system log errors"
mode: single
triggers:
- trigger: event
event_type: system_log_event
event_data:
level: ERROR
conditions:
- condition: template
value_template: "{{ trigger.event.data.name not in ['homeassistant.components.websocket_api.http.connection', 'homeassistant.helpers.event', 'aiohttp.server', 'custom_components.narodmon'] }}"
actions:
- action: rest_command.report_error_to_icinga2
data:
message: "{{ trigger.event.data.message[0] }}"
- delay: "00:05:00"Автоматизация такая же, как и в случае с Телеграмом, только используется другой action.
На этом, по сути, всё. Нужно только перезагрузить конфигурацию Home Assistant. Если в конфигах Icinga у вас включены уведомления, то на почту будут приходить вот такие сообщения:
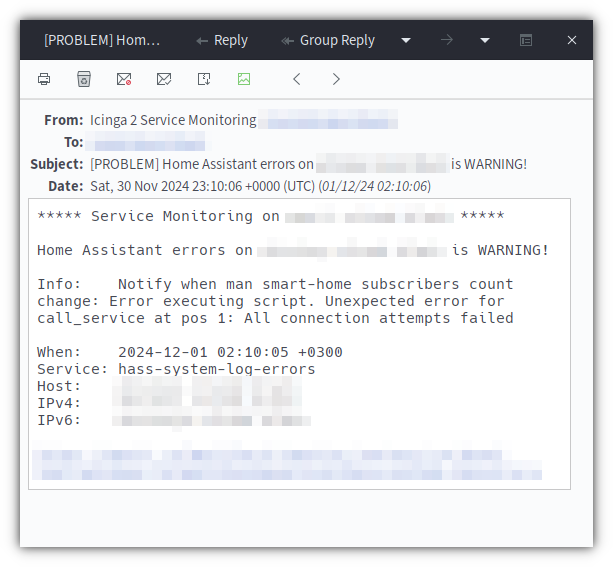
Не думаю, что много кто использует Icinga для мониторинга домашней инфраструктуры, но, надеюсь, было хотя бы познавательно 🙂